
Virtual Treadmill Revisited
I have been using various LLMs to help with data analysis and coding problems for a while. They can be frighteningly good at basic code (simple tasks such as data processing, porting code from one language to another and basic algorithms) and frustratingly bad at other tasks especially ones that use external libraries.
But as a fun exercise, and because I am generally interested in old demos, I wondered how long it would take ChatGPT to rebuild the Virtual Treadmill (VTM) concept. In the VTM, the user is instructed to walk on the spot in order to move forwards in the virtual world. The system recognises the walking from the movement of their heads. This was first presented at a workshop in 1993 (my first of many trips to Barcelona). It was followed up us, and then my other labs. It occasionally gets independently re-invented, and has appeared in some recent consumer games. The main drawbacks are typically that the recognition isn’t perfect and can occasionally over-shoot. Implementations need to worry about detecting foot falls and matching walking speeds. But it is one way of doing hand and device-free lomotion in VR.
The VTM was one of the first projects I worked on as a PhD student, based on a suggestion of my supervisor, Mel Slater. Mel also had been working on a neural network implementation for a separate purpose. The idea of recognising “gesture” from motion was out there (Apple Grafiti was already a thing), so not an unreasonable idea. But debugging the neural net code, then deciding the appropriate network structure and then training the network was the job of approximately 3 months of my time. My notes fill dozens of pages in the hardbound A4 notebooks I was recording all my work in at the time. With the size of the networks I was training at the time, discussed in more detail later, a training session would take about 4-8 CPU hours on our workstations
at the time (a mix of Sun workstations and an SGI Indigo that I had access to). So I would typically run 2-4 training sessions a day, mostly overnight when the labs were not in use. I would get to the lab, compare the overnight results to previous results in my notebook, and the set off the training again.
Eventually we settled on a few parameters which we could reliably train a working network. The input layer had 60 nodes, which was x,y,z position at 20 Hz. Two hidden layers of 20 and 10 nodes. One binary output layer indicating walking or not. Gathering training data was very simple: you just had to walk on the spot and press a button when you were walking. We also learnt that it was important to have good examples of both positive and negative training.
I am also a complete data nerd, so I have some of the original training data from 1993-1994 and later iterations of the demonstration (my labelling of my data has now much improved and I now put the year in my log files!).
So with the benefit of hindsight, we know a lot about the likely solution. We know we have good data that we know a network can be trained for. How long will it take us to redevelop the code and get a trained, working neural network with modern tools? The answer is less than 15 minutes. Indeed approximately 5 minutes to get the answer, and the rest of the time to build confidence that I wasn’t mis-believing the results.
With ChatGPT I started with the following series of prompts, which describes the input data and the neural network I want. I ask for it in a Jupyter notebook so I could easily share the results for this blog post. The code I got back took approximately 30 seconds to train on a modern GPU (my machine had a GeForce 3090 card in it), compared to 4-8 hours in code that we wrote that ran on 68030 CPUs in 1993/1994.
I want to build a "virtual treadmill" control system. It will take tracking information of the head of a VR user, at 20 Hz, and predict whether the user is walking on the spot or not. I have training data that looks like the following: 0.005504 -0.001709 0.001216 0 0.000207 -0.000773 -0.000556 0 -0.003840 0.000021 -0.002172 0 0.001921 -0.001316 -0.000164 0
I want to use Jupyter to write code. I want to build a neural network, with 60 input values, then two hidden layers of 20 and 10 nodes, and one output layer. I need code to train and test this network.
The proposed code did not use a sliding window, but reminding the LLM of the input data got a working system:
OK, I need the code to read the original file which looks like this: -0.002710 -0.000555 0.001380 0 0.001865 -0.000631 0.002400 0 -0.000678 0.000193 -0.000135 0 -0.002043 0.001376 -0.001057 0 -0.002660 0.000944 -0.002206 0 0.001890 -0.003162 -0.001233 0
The resulting Jupyter Notebook can be visualised here, and the code is on github.
My main interaction with the code was making sure that the training and test datasets were indeed isolated, checking how it was running the code. All seemed fine. So I also asked it to do something I had never done before: just plot the trajectory of the data coloured by state and correctness. Resulting in the following:
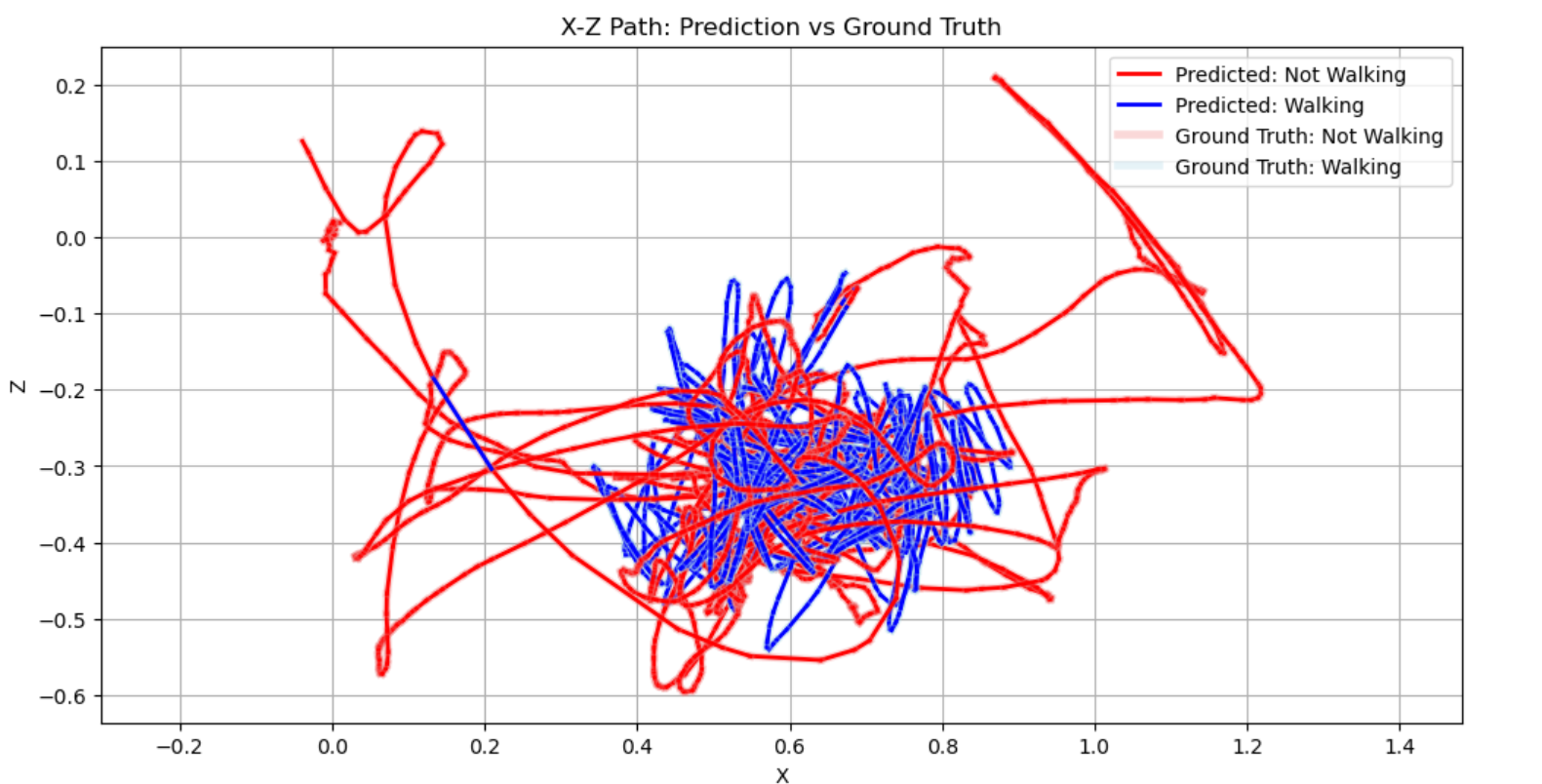
Then ChatGPT offered to write this out as a video (that didn’t work until I manually installed ffmpeg to my desktop).
I spent another four hours playing with different log files trying to re-create the different steps I played with (different coordinate
frames, multi-speed walking, the data from the UCL/UNC Siggraph 1999 paper which unfortunately I don’t have good enough notes about to reproduce).
What next? We used a Polhemus tracking system that could operate at 60 Hz, and even then it operated round-robin between the number of sensors attached (typically one for the head, one for the hand). My next job will be to record some new data from a Meta Quest 3 and release that code.




